A few months ago Siva Balakrishnan wrote a nice post on Larry Wasserman’s blog about the Chaudhuri-Dasgupta algorithm for estimating a density cluster tree. The method, which is described in a NIPS 2010 paper “Rates of convergence for the cluster tree” (pdf link), is conceptually simple and supported by nice theoretical guarantees but somewhat difficult to use in practice.
As Siva described, clustering is a challenging problem because the term “cluster” is often poorly defined. One statistically-principled way to cluster (due to Hartigan (1975)) is to find the connected components of upper level sets of the data-generating probability density function. Assume the data are drawn from density  and fix some threshold value
and fix some threshold value  , then the upper level set is
, then the upper level set is 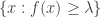 and the high-density clusters are the connected components of this set. Choosing a value for is difficult, so we instead find the clusters for all values of
and the high-density clusters are the connected components of this set. Choosing a value for is difficult, so we instead find the clusters for all values of 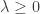 . The compilation of high-density clusters over all values yields the level set tree (aka the density cluster tree).
. The compilation of high-density clusters over all values yields the level set tree (aka the density cluster tree).
Of course, is unknown in real problems, but can be estimated by  . Unfortunately, computing upper level sets and connected components of is impractical. Chaudhuri and Dasgupta propose an estimator for the level set tree that is based on geometric clustering.
. Unfortunately, computing upper level sets and connected components of is impractical. Chaudhuri and Dasgupta propose an estimator for the level set tree that is based on geometric clustering.
- Fix parameter values
 and
and  .
.
- For each observation
 ,
, 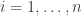 , set
, set  to be the distance from to ‘s
to be the distance from to ‘s 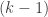 ‘th closest neighbor.
‘th closest neighbor.
- Let
 grow from
grow from  to
to  . For each value of :
. For each value of :
- Construct a similarity graph
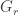 with node set
with node set  and edge
and edge  if
if  .
.
- Let
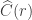 be the connected components of .
be the connected components of .
Chaudhuri and Dasgupta observe that for single linkage  and
and 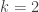 . The connected components also form a tree when compiled over all values of , which is the estimated level set tree.
. The connected components also form a tree when compiled over all values of , which is the estimated level set tree.
Using this estimator in practice is not straightforward, due to the fact that varies continuously from to . Fortunately, there is a finite set of values where the similarity graph can change. Let  be the set of edge lengths in the complete graph (aka
be the set of edge lengths in the complete graph (aka  ), and let
), and let 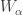 be the set with each member divided by . Then can only change at values in the set
be the set with each member divided by . Then can only change at values in the set
 .
.
The vertex set changes when when is equal to some edge length, because as grows, node  is first included in precisely when
is first included in precisely when  which is the ‘th smallest edge length incident to vertex . Similarly, the edge set changes only when is equal to an edge length divided by , because edge
which is the ‘th smallest edge length incident to vertex . Similarly, the edge set changes only when is equal to an edge length divided by , because edge  is first included in when
is first included in when  , which only happens if
, which only happens if  .
.
An exact implementation of the Chaudhuri-Dasgupta algorithm starts with equal to the longest pairwise distance and iterates over decreasing values in set  . At each iteration, construct and find the connected components. To illustrate, I sampled 200 points in 2-dimensions from a mixture of 3 Gaussians, colored here according to the true group membership.
. At each iteration, construct and find the connected components. To illustrate, I sampled 200 points in 2-dimensions from a mixture of 3 Gaussians, colored here according to the true group membership.
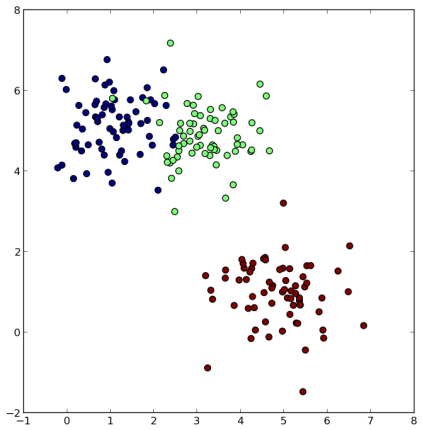
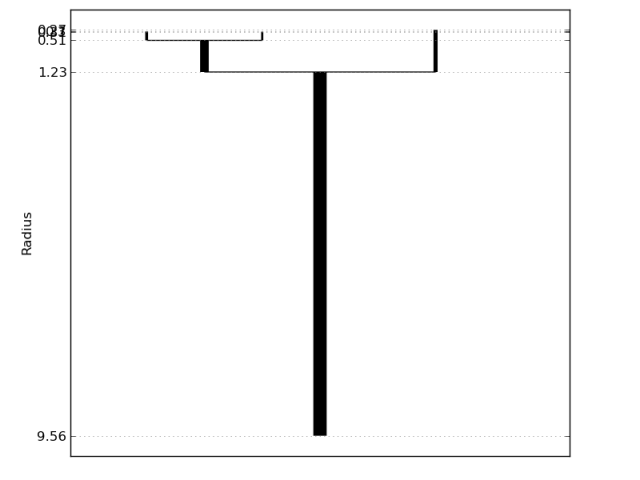 The second figure is a visualization of the Chaudhuri-Dasgupta level set tree for these data. Vertical line segments represent connected components, with the bottom indicating where (in terms of ) the component first appears (by splitting from a larger cluster) and the top indicating where the component dies (by vanishing or splitting further). The longer a line segment, the more persistent the cluster. The plot clearly captures the three main clusters.
The second figure is a visualization of the Chaudhuri-Dasgupta level set tree for these data. Vertical line segments represent connected components, with the bottom indicating where (in terms of ) the component first appears (by splitting from a larger cluster) and the top indicating where the component dies (by vanishing or splitting further). The longer a line segment, the more persistent the cluster. The plot clearly captures the three main clusters.
There are many ways to improve on this method, some of which are addressed in our upcoming publications (stay tuned). A Python implementation of the Chaudhuri-Dasgupta algorithm will be available soon. In fact, the code is already available at https://github.com/CoAxLab/DeBaCl/ in the “develop” branch. Accompanying demos, tutorials, and documentation will be posted shortly.
References
- Chaudhuri, K. and DasGupta, S. (2010). Rates of convergence for the cluster tree. Advances in Neural Information Processing Systems, 23, 343–351.
- Hartigan, J. (1975). Clustering Algorithms. John Wiley & Sons.




